Verantwoord analyseren, interpreteren en presenteren in SPSS Statistics
Een rijke historie: Dialoogvensters in SPSS Statistics
- Leestijd: 10 minuten
- Niveau: Beginner
- Voorkennis: Basiskennis IBM SPSS Statistics
Samenvatting
- Verschillen tussen meetniveau's
- Rollen van variabelen instellen
- Correct gebruik van dialoogvensters
- Verschillen tussen de drie types van dialoogvensters
Auteur(s)
- Jos den Ronden, Data Analyse Academie
- Rianne Severin-Hotting, DASC
Verder verdiepen?
IBM SPSS Statistics kent een rijke historie. Al in de jaren 80 had de software met de eerste desktop versie, SPSS/PC+, een grafische interface. In de jaren 90 zagen we flarden hiervan terug in de dialoogvensters van het toenmalige SPSS for Windows. De laatste 30 jaar zijn er nog vele nieuwe procedures aan de software toegevoegd, met dialoogvensters die qua vormgeving steeds nieuwe features brachten.
Momenteel hebben we drie generaties dialoogvensters in IBM SPSS Statistics, elk met een eigen look & feel. Dit kan vooral voor nieuwe gebruikers enigszins verwarrend zijn. Tegelijkertijd kunnen gebruikers die al langere tijd met IBM SPSS Statistics werken verrast worden door de opties die een dialoogvenster wel of juist niet te bieden heeft.
In dit artikel staan we dan ook stil bij de drie typen dialoogvensters, zodat je de verschillen tussen de dialoogvensters leert herkennen en, bovenal, er rekening mee kunt houden
Het begrip meetniveau
Om de verschillen tussen dialoogvensters inzichtelijk te maken hebben we het begrip meetniveau van een variabele nodig. Heel in het kort: met het begrip meetniveau kunnen we een onderscheid maken tussen variabelen op basis van wat de waarden van een variabele voorstellen. IBM SPSS Statistics onderscheidt 3 meetniveaus:
- Nominaal: de waarden van een variabele zijn feitelijk codes die de antwoordcategorieën representeren; welke code je aan welke categorie toekent is volkomen arbitrair. De codering van bijvoorbeeld een variabele geslacht kan zijn 1 voor Man, 2 voor Vrouw, 3 voor Non-binair, maar even valide is 1 voor Non-binair, 2 voor Vrouw, en 3 voor Man. De codes zijn alleen maar bedoeld om de verschillende antwoordmogelijkheden te benoemen (nomen = benoemen).
- Ordinaal: De codes zijn niet arbitrair maar weerspiegelen de ordening in de antwoordcategorieën; zo is een natuurlijke codering voor een variabele leeftijdsklasse: 1 voor Jong, 2 voor Middelbaar, en 3 voor Ouder. Een codering zoals 1 voor Ouder, 2 voor Jong, en 3 voor Middelbaar is niet alleen onhandig maar vraagt om problemen.
- Schaal: De waarden vertegenwoordigen geen codes maar zijn meetwaarden op een bepaalde schaal. Zo kun je een variabele inkomen hebben, met een waarde die het inkomen in euro’s aangeeft.
In de dialoogvensters van IBM SPSS Statistics zie je dan ook de volgende icoontjes bij de variabelen:
Nominaal, de codes representeren gelijkwaardige categorieën. Voorbeelden van variabelen: geslacht, etniciteit, regio, branchecode
Ordinaal, de codes representeren categorieën die geordend zijn. Voorbeeld van variabelen: leeftijdsklasse (van jong naar ouder), inkomensklasse (van laag naar hoog), opleiding (van laag naar hoog).
Schaal, de waarden vormen een schaal. Voorbeeld van variabelen: inkomen (in euro’s), leeftijd (in jaren) en lengte (in cm).
Look & Feel herkennen in dialoogvensters
In het licht van meetniveaus lopen we de 3 generaties dialoogvensters langs.
Opmerking: We werken in de voorbeelden met survey_sample.sav; dit bestand vind je in de Samples map, een submap van de map waarin IBM SPSS Statistics is geïnstalleerd. Als je wilt kun je het hier gepresenteerde zelf uitvoeren in IBM SPSS Statistics.
Type 1
Het eerste type dialoogvenster, met als voorbeeld Frequencies, houdt geen rekening met meetniveaus. Je kunt van elke variabele statistieken opvragen, ongeacht of die nu betekenis hebben of niet.
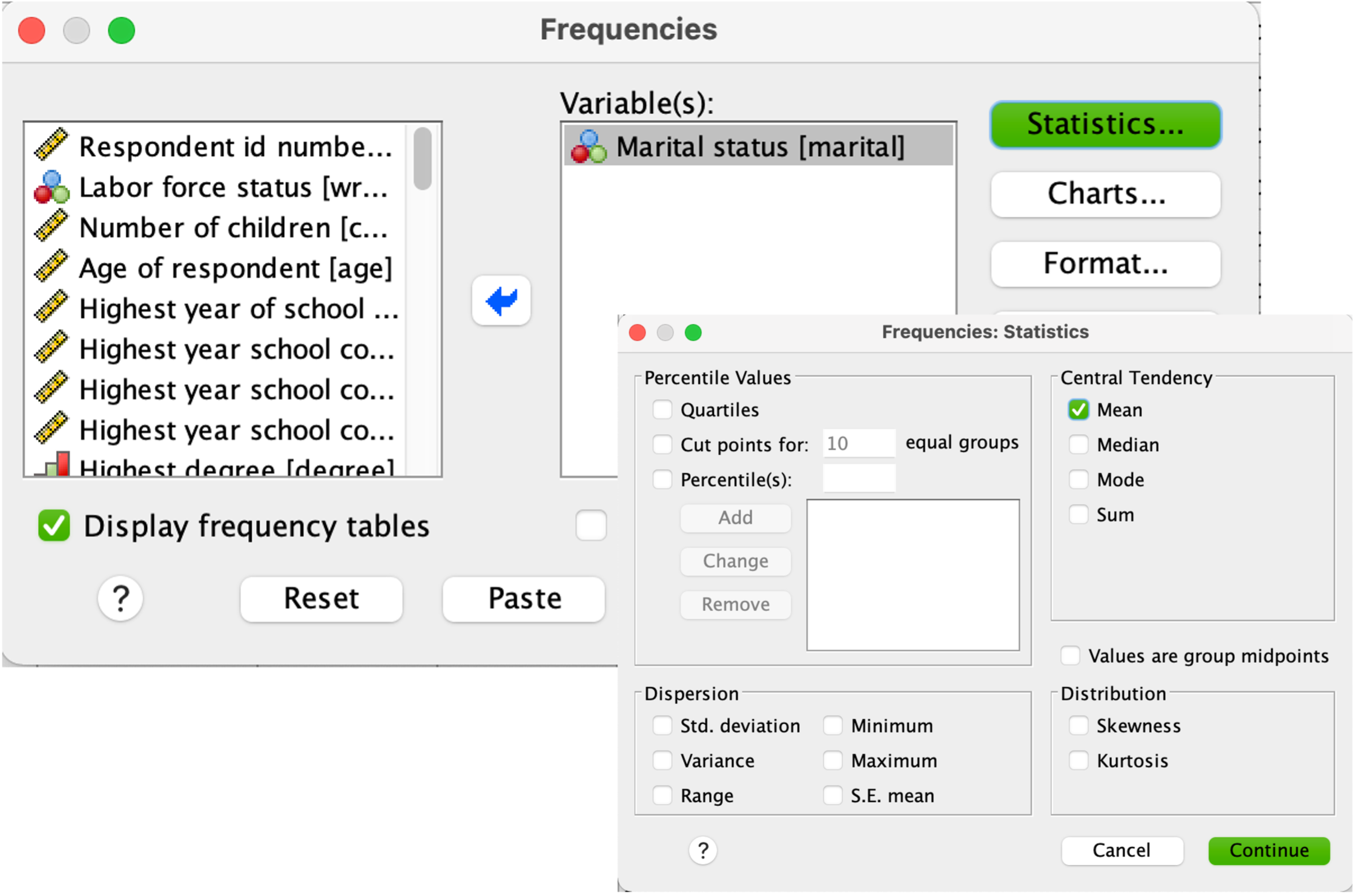
Hieronder zie je de uitvoer van Frequencies voor de variabele Marital status.
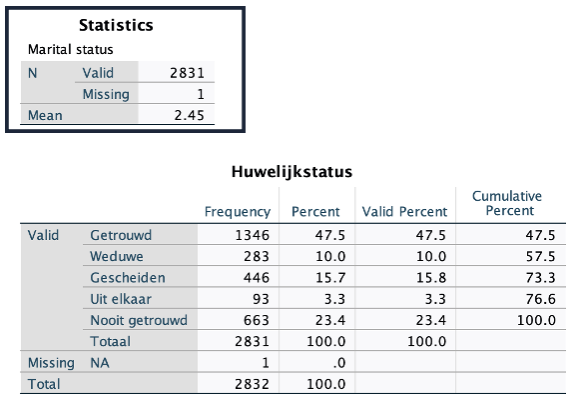
Frequencies heeft geen enkele moeite met het uitrekenen van de gemiddelde huwelijkse staat, hier 2,45. Alleen, dit gemiddelde zegt niets. De huidige codering is dat 1 staat voor Getrouwd en 5 voor Nooit getrouwd. Maar, hadden we gekozen voor bijvoorbeeld 1 voor Nooit getrouwd en 5 voor Getrouwd, dan was daar een ander gemiddelde uitgekomen. Het gemiddelde is in dezen een nietszeggende statistiek voor een nominale variabele, ook al laat het dialoogvenster Frequencies dit toe.
Maar wat in een dialoogvenster zoals Bivariate Correlations? Ook dit is een eerste generatie dialoogvenster en houdt dus geen rekening met het meetniveau van de variabelen: je kunt elke variabele opnemen in dit dialoogvenster (mits numeriek). De correlaties worden keurig uitgerekend, maar de grote vraag is: hebben deze betekenis?
Dit hangt van het meetniveau van de variabele en het is aan de gebruiker om na te gaan of een bepaalde statistiek betekenis heeft gegeven het meetniveau van de variabele in kwestie. Of, anders gezegd, ook al kun je een bepaalde statistiek uitrekenen in IBM SPSS Statistics, dat wil niet per sé zeggen dat de statistiek ook zinvol is.
Type 2
Custom Tables
Het tweede type dialoogvenster, zoals Custom Tables, houdt wél rekening met meetniveaus. Wanneer je in het menu van SPSS kiest voor Analyze -> Tables -> Custom Tables, krijg je allereerst een melding over meetniveaus
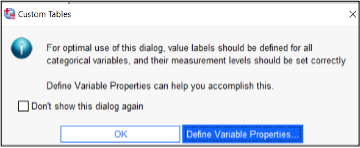
De melding komt er op neer dat het meetniveau van de variabelen correct moet zijn om de tabel te maken die je in gedachten hebt. Door op Define Variable Properties te klikken krijg je de mogelijkheid om de meetniveaus te checken en daar waar nodig te wijzigen.
In het dialoogvenster van Custom Tables zie je opnieuw de icoontjes van de meetniveaus. Als we een categorische variabele nemen zoals bijvoorbeeld gender en deze naar de rij of kolom van de tabel slepen, dan worden de categorieën automatisch weergegeven. Voor een schaalvariabele, bijvoorbeeld age, wordt automatisch het gemiddelde gepresenteerd
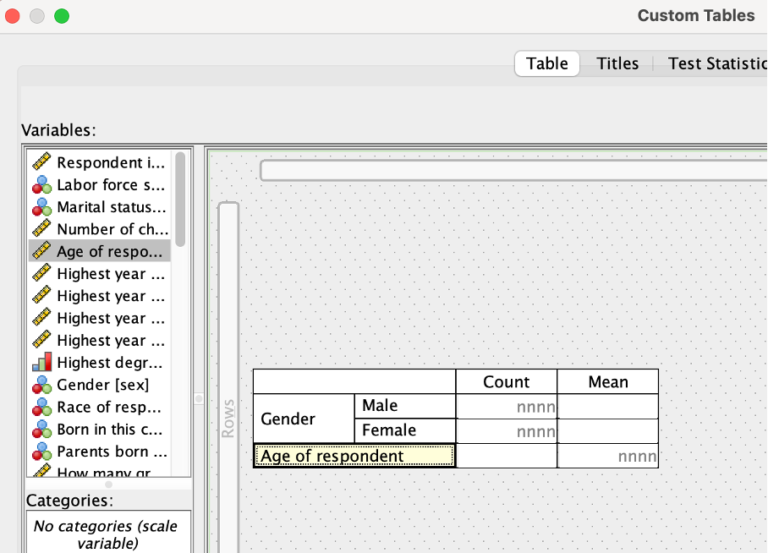
Het feit dat het dialoogvenster Custom Tables rekening houdt met de meetniveaus van de variabelen kan je ook anders bekijken: het zal je nooit lukken om een gemiddelde op te vragen van een variabele als die variabele nominaal of ordinaal is. En van hetzelfde laken een pak: je zult nooit de categorieën zien van een variabele als die variabele het schaal meetniveau heeft.
Het kan natuurlijk gebeuren dat je pas in het dialoogvenster van Custom Tables merkt dat het meetniveau van een variabele verkeerd staat. Gelukkig kun je het meetniveau van een variabele ook tijdelijk aanpassen in het Custom Tables dialoogvenster zelf: klik met de rechtermuis op de variabele waarna je het meetniveau van een variabele kunt bepalen. “Tijdelijk”, want het geldt alleen maar voor Custom Tables. Om het meetniveau definitief vast te leggen kun je in het menu Data -> Variable Properties gebruiken.
Visual binning
Een ander voorbeeld van een dialoogvenster dat rekening houdt met het meetniveau van de variabelen is Visual Binning. (Visual Binning, in het menu Transform, maakt klassen van het type: van <waarde 1> tot <waarde 2> wordt klasse 1, van <waarde 2> tot <waarde 3> wordt klasse 3 , etcetera; het is een heel snel alternatief voor Recode.) Het kan gebeuren dat de variabele op basis waarvan je de klassenindeling wilt maken ontbreekt in dit dialoogvenster. Reden: in het Visual Binning-dialoogvenster worden alleen ordinale en schaal variabelen getoond en de variabele in kwestie is als nominaal gedefinieerd.
Een goed voorbeeld van het verschil tussen de beide typen dialoogvensters vind je overigens in het Graphs menu, waar je het dialoogvenster van de Chart Builder (tweede type, je kunt alleen een Bar chart opvragen van een nominale of ordinale variabele)) eens kunt vergelijken met dat van Bar (eerste type, je kunt een Bar Chart opvragen van elke variabele, ook al levert dat een nonsense grafiek op).
Type 3
Het derde type dialoogvenster houdt rekening met meetniveaus en maakt gebruik van de rol die aan een variabele is toebedeeld.
Ter illustratie zien we hieronder het dialoogvenster van de procedure Automatic Linear Modeling. (Automatic Linear Modeling is een alternatief voor de procedure Regression. Beide procedures voorspellen een bepaalde variabele, de doelvariabele, ofwel target, op basis van een aantal voorspellende variabelen, de predictors of inputs).
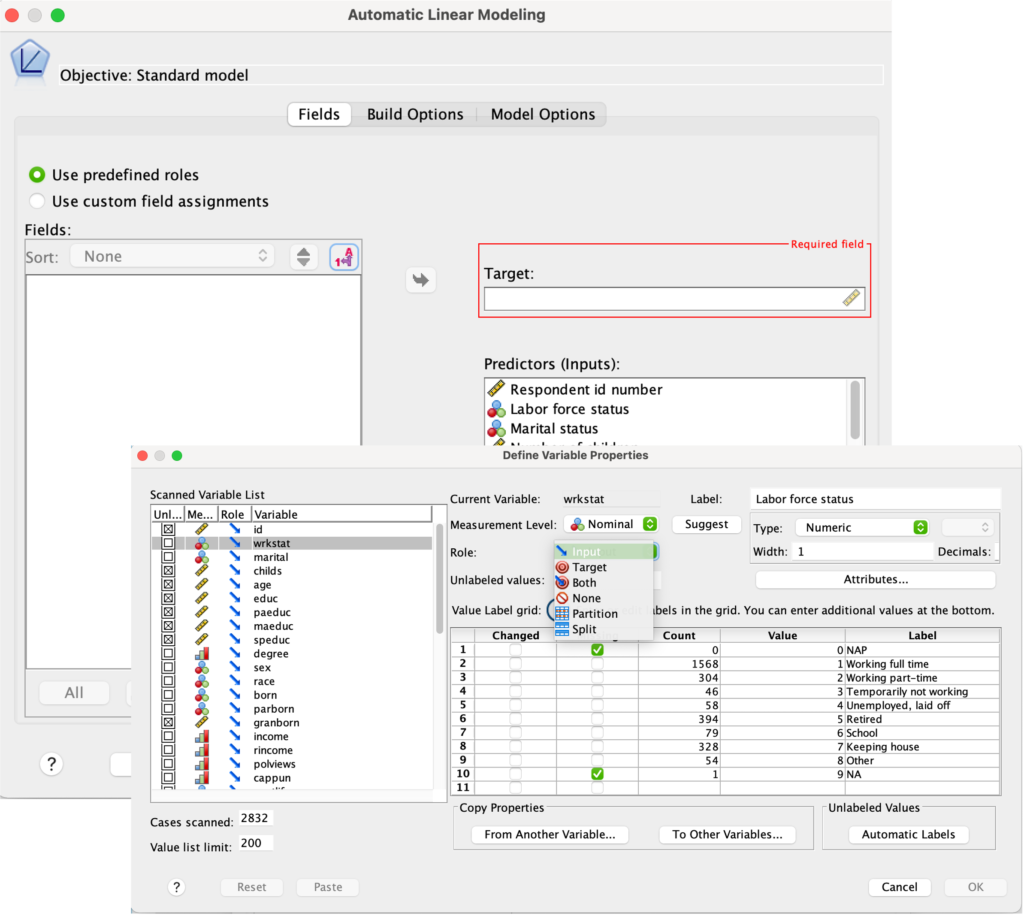
Getuige het schaal icoontje bij Required field moet het meetniveau van de doelvariabele schaal zijn, terwijl de predictoren elk meetniveau kunnen hebben. Dus ook in dit dialoogvenster zien we dat met meetniveaus rekening wordt gehouden. Hier is echter meer aan de hand…
De variabelen staan niet klaar in de variabelenlijst links (onder Fields), maar zijn alvast ingevuld onder Predictors (Inputs). De reden is dat dit dialoogvenster gebruik heeft gemaakt van de Role eigenschap van een variabele. Zoals alle variabele-eigenschappen kan je rollen op verschillende manieren vastleggen.
De eerste mogelijkheid is om dit rechtstreeks in de Variable View aan te passen. De tweede optie is via de Define Variable Properties (Data -> Define Variable Properties) zoals je ook in bovenstaande afbeelding ziet.
Als je wilt dat de variabelen nooit voor-ingevuld worden in dit type dialoogvenster, zet de rol voor alle variabelen dan op None.
Tip: dit gaat het snelst via Syntax.
Conclusie
In dit artikel hebben we stil gestaan bij de drie typen dialoogvensters die je ziet in IBM SPSS Statistics.
Het eerste type (a la Frequencies) houdt geen rekening met meetniveaus en rollen; wat betreft het meetniveau is het daarom aan de gebruiker om te beseffen dat allerhande statistieken niet per sé zinvol zijn alleen maar omdat ze in het dialoogvenster kunnen worden opgevraagd.
Het tweede type dialoogvenster (zoals Custom Tables) houdt wel rekening met meetniveaus maar niet met rollen; wanneer je dit type dialoogvenster oproept zal IBM SPSS Statistics eerst vragen of variabelen de juiste meetniveaus hebben en de gelegenheid bieden om het meetniveau van een variabele te veranderen. Hou er rekening mee dat het meetniveau van een variabele dicteert welke statistieken je vervolgens wél en welke statistieken je níet kunt opvragen.
Het meest recente type dialoogvenster (denk aan Automatic Linear Modeling) houdt ook rekening met meetniveaus en herkent bovendien de rol die aan variabelen is toebedeeld. Hier kun je je voordeel mee doen door allereerst de rol van een variabele vast te leggen waarna alle dialoogvensters van dit type die rol zullen respecteren.
IBM SPSS Statistics: What’s Next?
Zoals gezegd, IBM SPSS Statistics kent nogal wat historie en elke versie komt er functionaliteit bij. Zo zijn er weinig-bekende opties die het werken met IBM SPSS Statistics enorm vergemakkelijken. Wil je je je kennis van IBM SPSS Statistics opfrissen of leren welke handige features de laatste jaren zijn toegevoegd aan de software, dan verwijzen we graag naar het beschikbare cursusaanbod van DASC en de Data Analyse Academie. Cursussen verzorgen we ook in-company of in de vorm van 1-op-1 coaching on the job.
Happy learning en stay tuned!
Jos den Ronden, Data Scientist, Data Analyse Academie
Rianne Severin-Hotting, Data Scientist, DASC B.V.

Optimaal gebruik maken van SPSS Statistics?
We starten compact, zodat u groots kunt finishen. Door het afgebakende vraagstuk ziet u snel resultaat.